
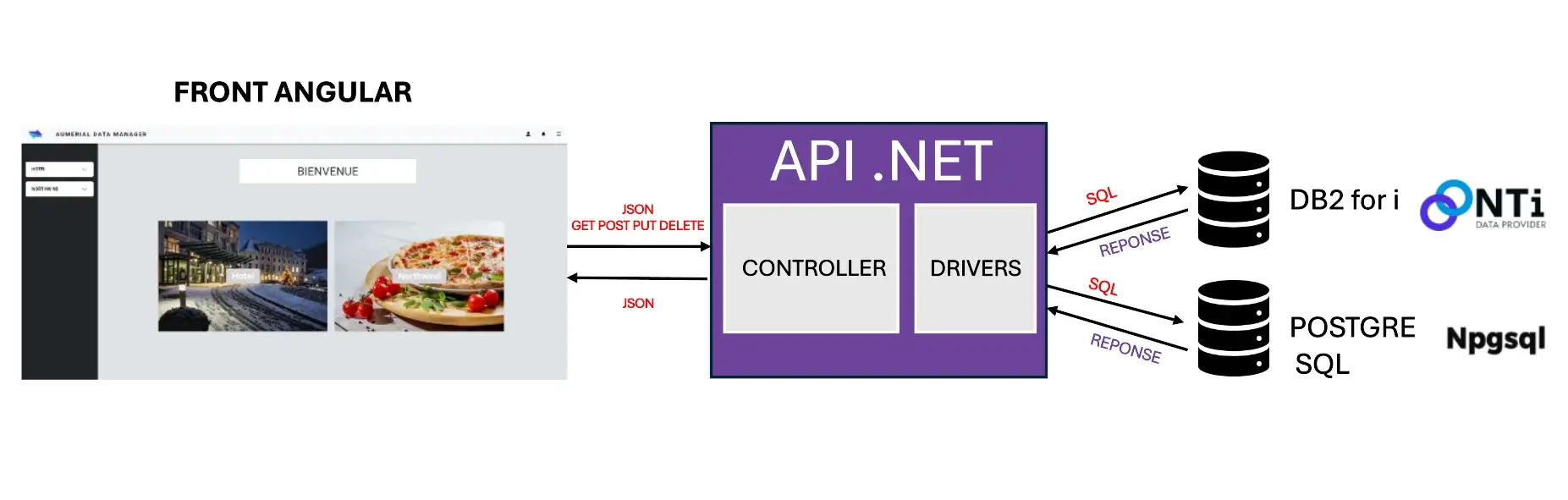
As a developer, I wanted to demonstrate and share how easy it is to use the NTi data access provider on a DB2 for i database, through a short article and an interesting specific project: develop a .NET API that can communicate with several databases, DB2 for i on an IBM i partition, and PostgreSQL containerized on a Raspberry pi itself connected to the IBM i.
The idea is to develop a parallel client-side application that can retrieve data in JSON format directly from this API, and display it in a dynamic, modular and modern way.
I've already built a few Front-end applications with Nuxt JS, but I've never tested the Angular JS framework, so this will be a great way for me to discover TypeScript.
API creation
Step 1: Setting up the work environment
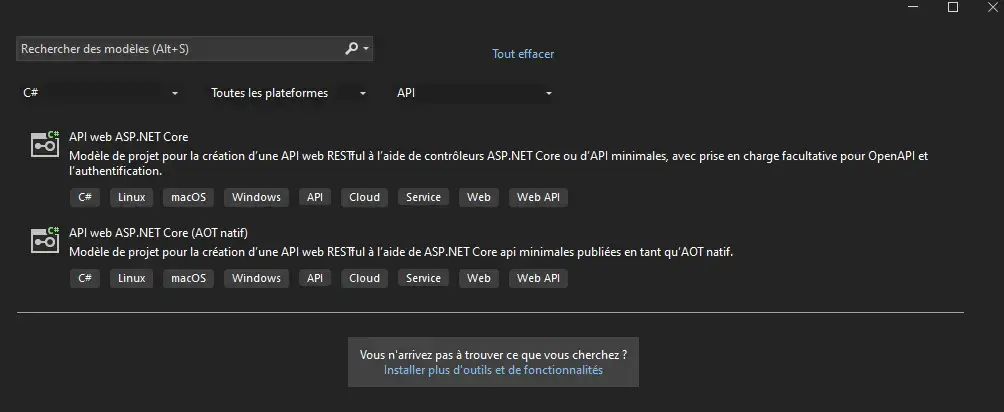
So I'm starting with the ASP .NET API environment directly from Visual Studio, which offers a ready-to-use configuration, with key tools like Swagger, naturally integrated into the .NET ecosystem and allowing you to test your API efficiently natively without the need to use POSTMAN.
To enable SQL queries on any database, you need the right data provider (driver), each one respecting the ADO.NET standards, which represent a set of classes designed to facilitate data access for .NET applications.
This means you can manipulate data (read, write, update, delete) using familiar objects and methods (SQL command support, connection management, transaction execution, query result manipulation, etc.).
So I choose :
- NTi for DB2 for i
- NPGSQL for PostgreSQL
These 2 providers are referenced in NuGet, and the NTi license key is already integrated into the IBM i. All I have to do is download them as a dependency of my project, and I'm ready to go.
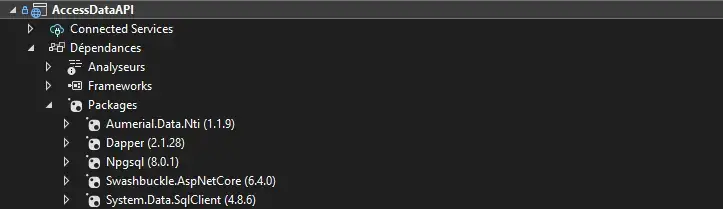
Then, I install Dapper, a lightweight, opensource ORM designed by the StackOverflow team to query these 2 databases. The automatic mapping of entities is an obvious time-saver.
I'm now able to set up CRUD operations and highlight the simplicity of query execution. In particular, NTi connects to DB2 for i with no driver, no overlay and no constraints: all you have to do is configure the connection string in the program.

Step 2: Data modeling and Service configuration
Once I've integrated the data providers needed for my project, I'll get to work on the internal structure of the API.
I start by defining the various data models, to ensure that their handling and the exchanges between the API and the 2 databases are structured.
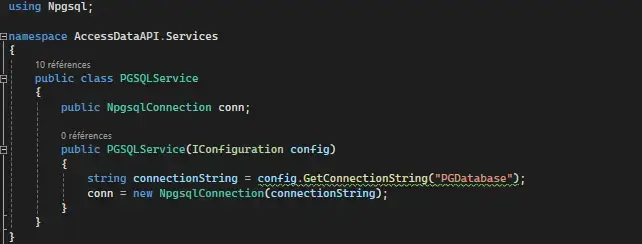
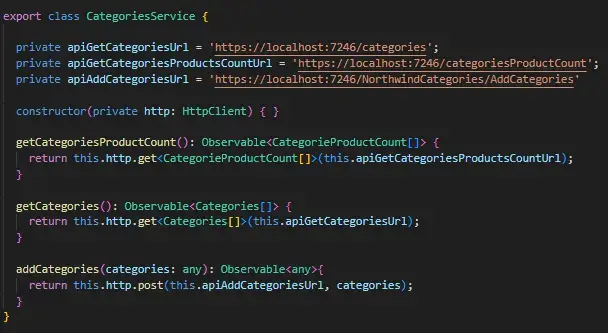
For each database, I set up separate connection services using the two data providers mentioned above, to establish a secure and efficient connection, enabling the API to execute SQL queries.
DB2Service:
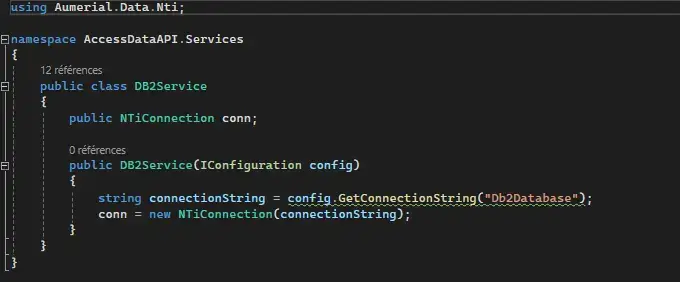
PGSQLService:
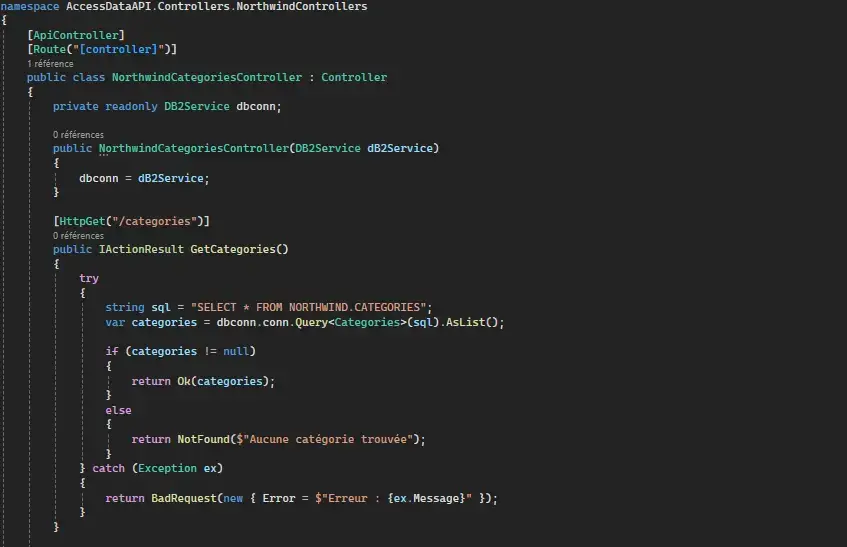
With the models and services in place, I can create the controllers. They process incoming requests, execute the necessary logic (CRUD) and return the appropriate responses to clients.
GET request to retrieve categories:
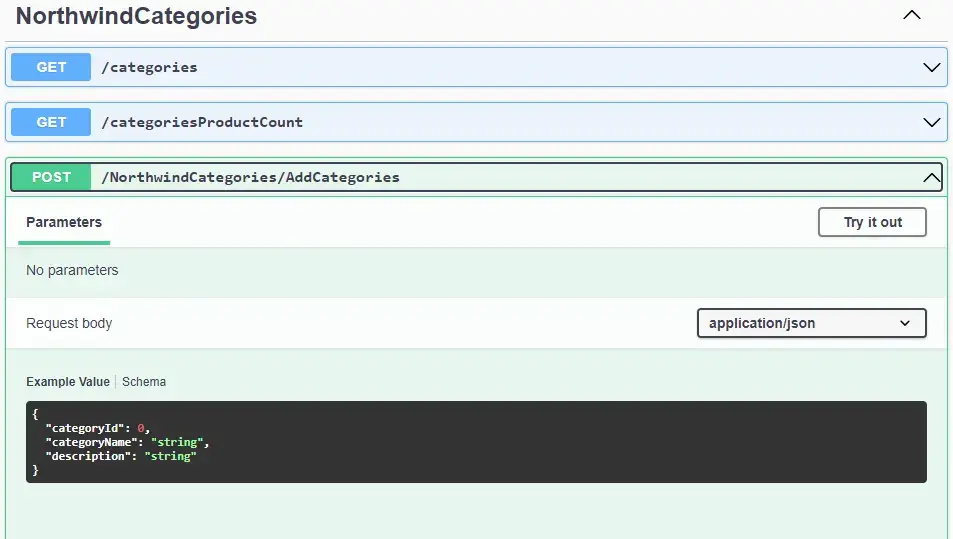
POST request to add a new category:
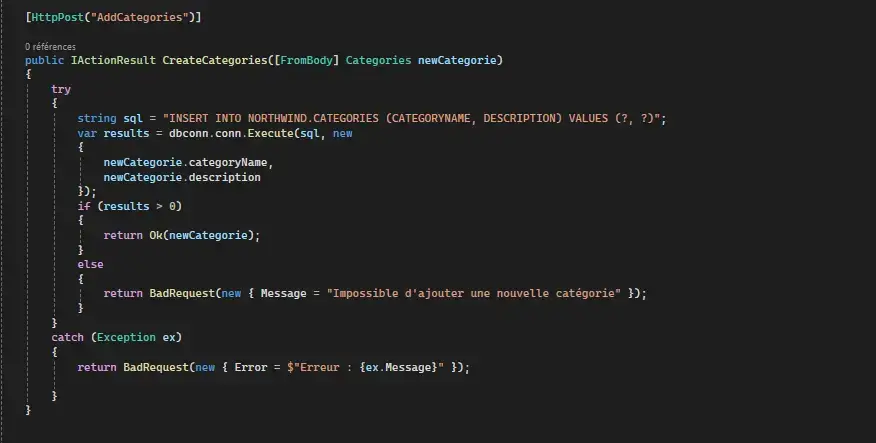
To ensure that HTTP requests are correctly routed to the controllers' actions, I've set up a precise routing system. Routes associate specific URLs with controller actions, ensuring that each request reaches its intended API destination.
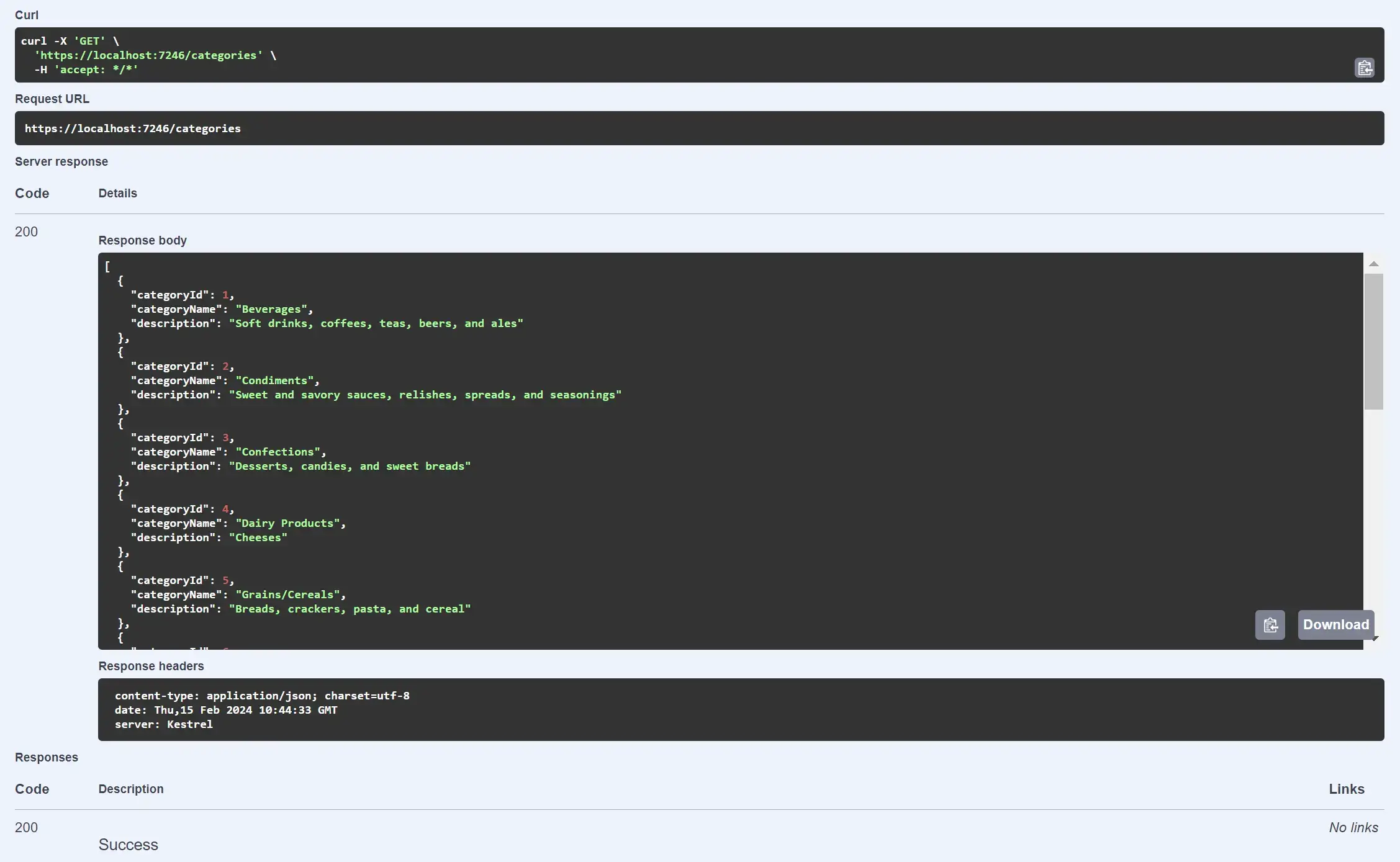
GET request result in Swagger:
API request schema for adding a new category (POST)
Finally, to enable the external application to retrieve data from the .NET API, I add a CORS (Cross Origin Resource Sharing) configuration to securely authorize cross-domain requests, ensuring that the Angular application can access API resources without violating the same-origin policy.
With the API now configured and functional, it's now ready to use and paves the way for the next step, the creation of the front-end application.
Creation of the Angular application
Step 1: Angular environment configuration
I start by setting up the necessary development environment for Angular using Node.JS and NPM, and installing the Angular Cli packages. With the MVVM design model, the idea is to separate display logic from business logic. This time, I'm using Visual Studio Code, with some practical extensions that enable me to develop faster.
Step 2: Creation of services and data model.
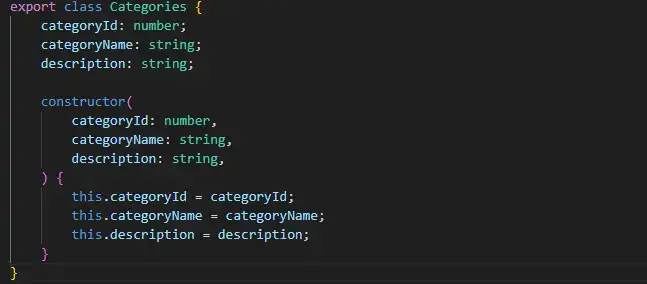
In the same way as the .NET API, I also create TypeScript data models for more efficient handling, storage and use of this data in the application.
Communication with the .NET API is established via the services offered by Angular, using the HTTP protocol to exchange data in JSON format.
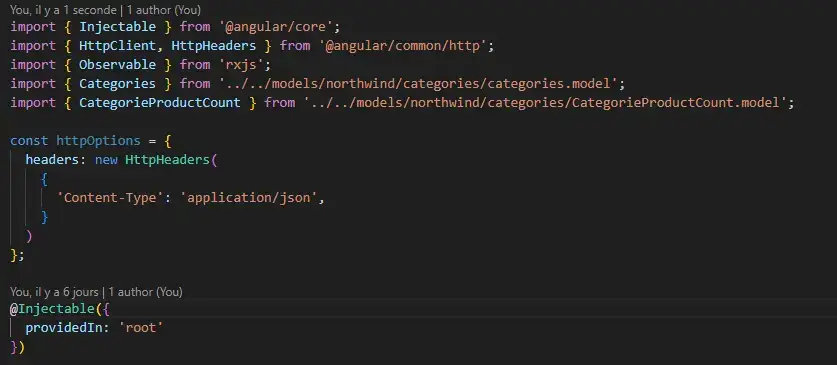
So I create different services that act as a bridge between the Angular application and the .NET API. Each method uses a specific URL, and I can now call the methods corresponding to each service directly from each Angular component.
Step 3: Development of Angular components
Angular's main advantage lies in its use of components, consisting of a TypeScript file for data manipulation and business logic, an HTML file for templates, and a css or scss file for styling. These components can be nested within one another, promoting modularity.
By creating separate components for different parts of the user interface, I was able to call the methods defined in the Angular services to retrieve data from the API.
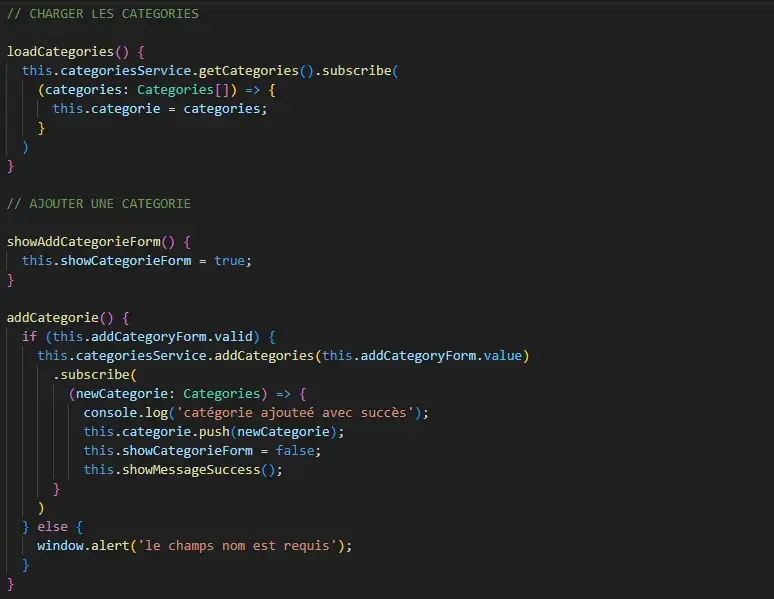
This makes it easy to create more or less complex graphs or calculations to meet specific needs, while benefiting from dynamic updating of the user interface and extremely low response times.
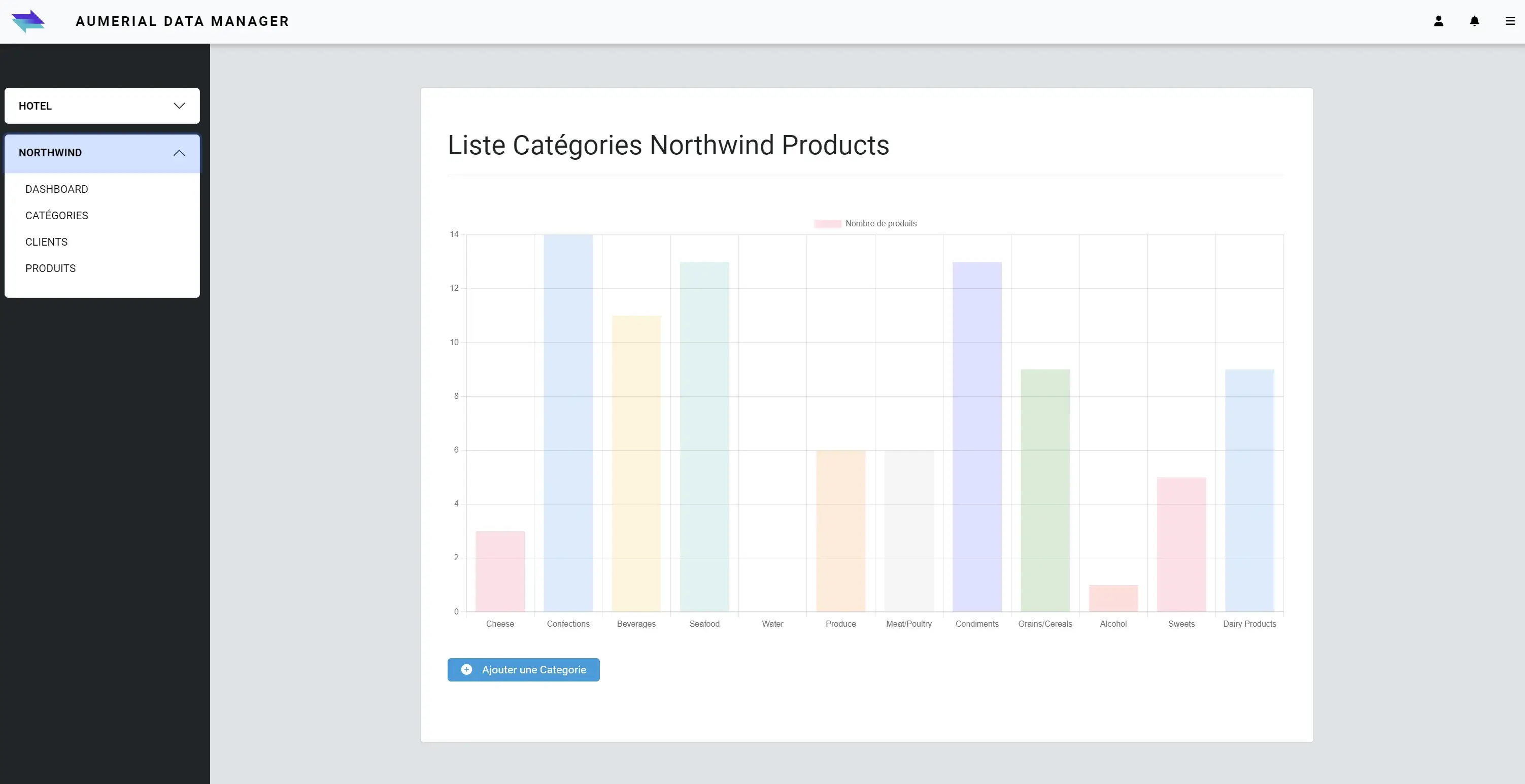
Creation of a bar chart, to retrieve the number of products per category:
visual of the bar chart, from my Angular front-end application :
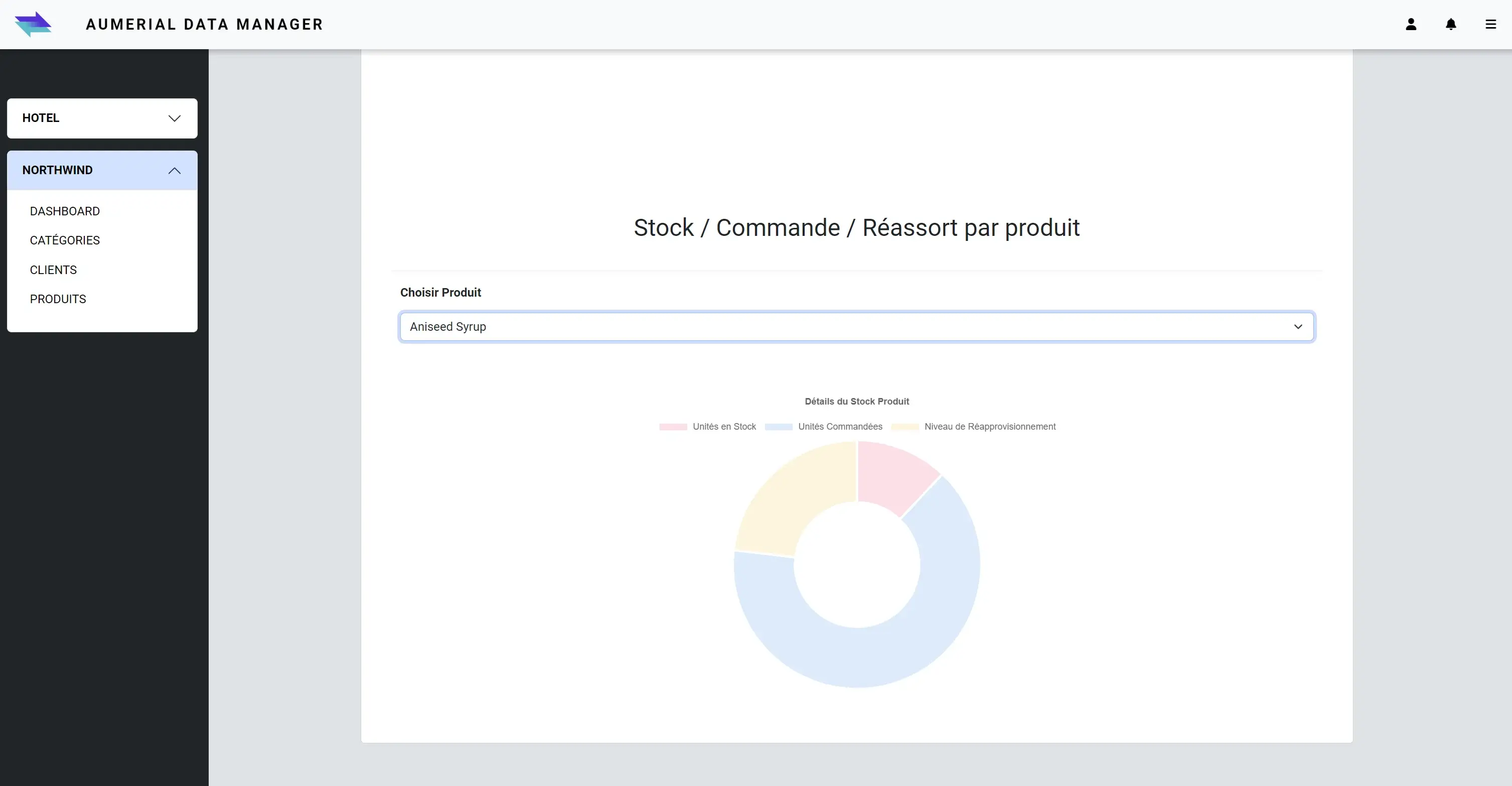
visual of a pie chart showing product inventories:
Conclusion
This project illustrates the gains in productivity and modularity offered by the .NET ecosystem, but above all it is an eloquent demonstration of the simplicity and efficiency of NTi for data access on IBM i, and for the creation of fat-client applications.
With a good understanding of object-oriented programming principles, ADO .Net standards and, of course, SQL language, whatever the underlying DBMS, modern development and communication with various databases becomes truly accessible, easy and free of constraints.
What I quickly came up with is a perfect illustration of one of the countless possibilities offered by our Nti data provider, which highlights the importance of having simplified, rapid access to the resources of systems as robust as the IBM i. These resources become not only accessible but also fully exploitable for the development of business applications specific to each need, without added complexity.
The realization of a .NET API capable of dialoguing simultaneously with DB2 for i on an IBM i partition and a PostGreSQL instance containerized on a Raspberry Pi connected to the IBM i illustrates the versatility and efficiency of our NTi data provider in orchestrating perfect communication while skilfully blending traditional and modern resources.
Quentin Destrade