
Contexte
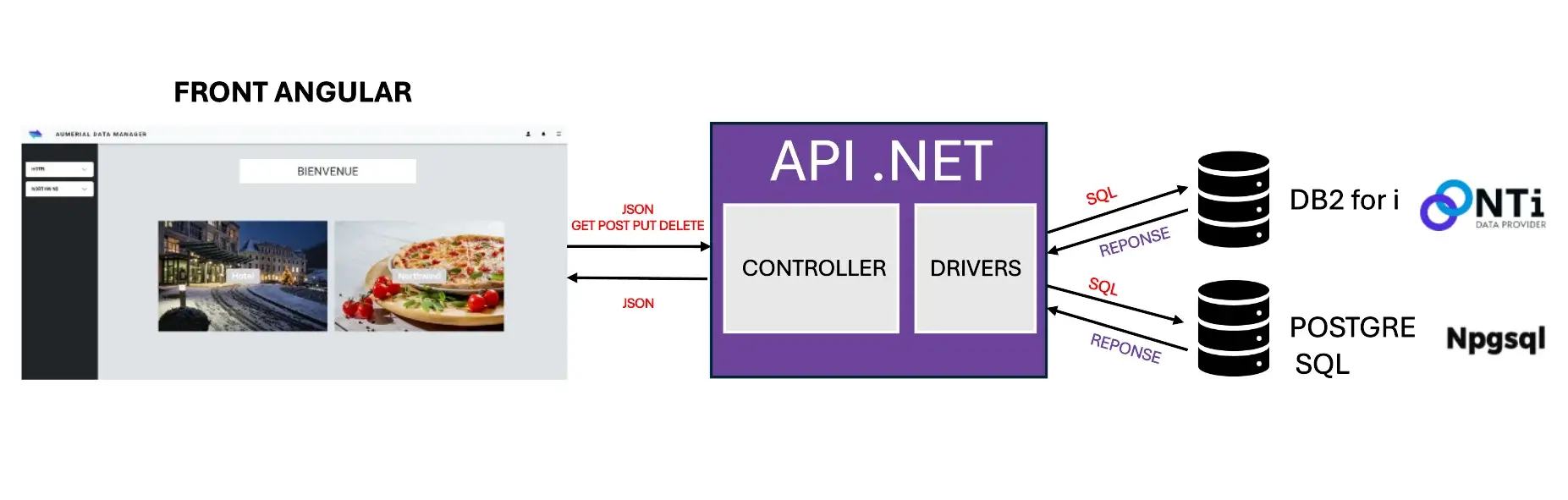
En tant que développeur, j’ai souhaité démontrer et partager la simplicité d’utilisation du fournisseur d’accès aux données NTi sur une base de donnée DB2 for i, au travers d’un petit article et d’un projet spécifique intéressant:
Développer une API .NET capable de communiquer avec plusieurs bases de données, DB2 for i sur une partition IBM i, et PostgreSQL conteneurisée sur un Raspberry pi lui-même connecté à l’IBM i.
L’idée est de développer en parallèle une application côté client, qui puisse récupérer directement depuis cette API les données au format JSON, et les afficher de manière dynamique, modulaire et moderne.
J’ai déjà réalisé quelques applications Front avec Nuxt JS, mais je n’ai jamais testé le framework JS Angular, ce sera un excellent moyen pour moi de découvrir TypeScript.
Création de l’API
Etape 1 : Configuration de l’environnement de travail
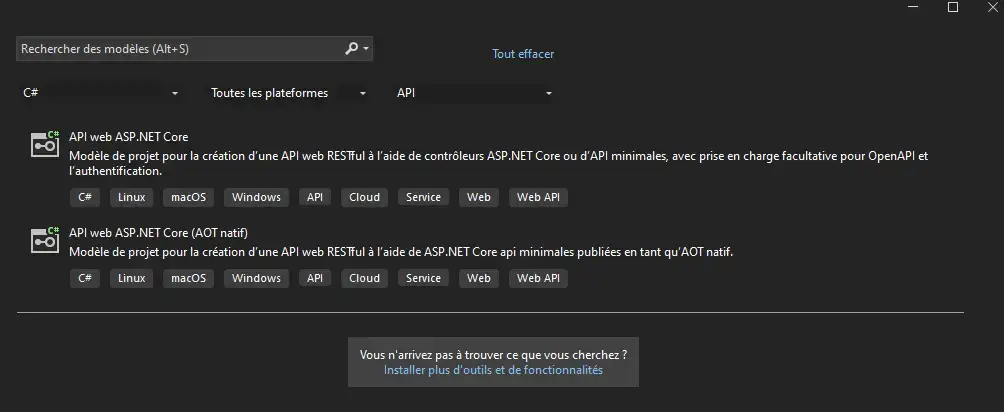
Je démarre donc avec l’environnement ASP .NET API directement depuis Visual Studio, qui offre une configuration prête à l’emploi, avec des outils clés comme Swagger, intégré naturellement dans l'écosystème .NET et qui permet de tester son API de manière efficace nativement sans avoir besoin d’utiliser POSTMAN.
Pour permettre d’effectuer des requêtes SQL sur n’importe quelle base de données, il faut le fournisseur de données (pilote) adéquat, chacun respectant les standards ADO.NET qui représentent un ensemble de classe conçues pour faciliter l’accès aux données pour les applications .NET.
On peut ainsi manipuler les données (lire, écrire, mettre à jour, supprimer) en utilisant des objets et méthodes familiers (prise en charge des commandes SQL, gestion des connexions, exécution des transactions, manipulation des résultats de requête, etc…).
Je choisis donc :
NTi pour DB2 for i
NPGSQL pour PostgreSQL
Ces 2 providers sont référencés dans NuGet, la clé de licence NTi est déjà intégrée dans l’IBM i, je n’ai plus qu’à les télécharger en tant que dépendance de mon projet et le tour est joué.
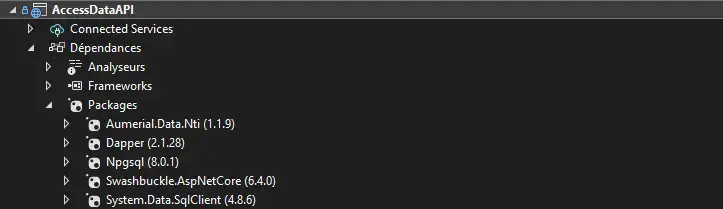
J’installe ensuite Dapper, un ORM léger et opensource conçu par l’équipe de StackOverflow pour requêter ces 2 bases de données ; le mappage automatique des entités présente un gain de temps évident.
Je suis désormais en mesure de pouvoir établir les opérations CRUD et mettre en avant la simplicité d'exécution des requêtes. Notamment avec NTi qui se connecte à DB2 for i sans driver, sans surcouche et sans contrainte, il suffit simplement de configurer la chaine de connexion dans le programme.

Etape 2 : Modélisation de données et configuration des Services
Après avoir intégré les fournisseurs de données nécessaires à mon projet, je m’attelle à la structure interne de l’API.
Je commence par définir les différents modèles de données, pour m’assurer que leur manipulation et que les échanges entre l’API et les 2 bases de données soient structurés.
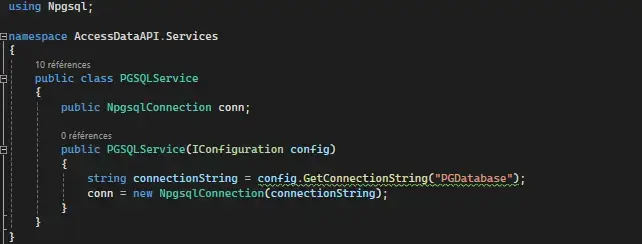
Pour chaque base de données, je configure des services de connexion distincts en utilisant les deux data provider cités précédemment, afin d’établir une connexion sécurisée et efficace, permettant à l’API d’exécuter des requêtes SQL.
DB2Service:
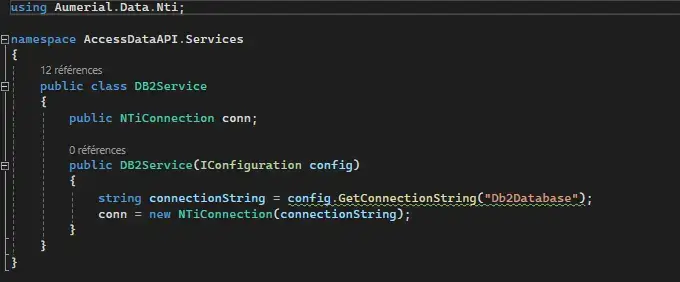
PGSQLService:
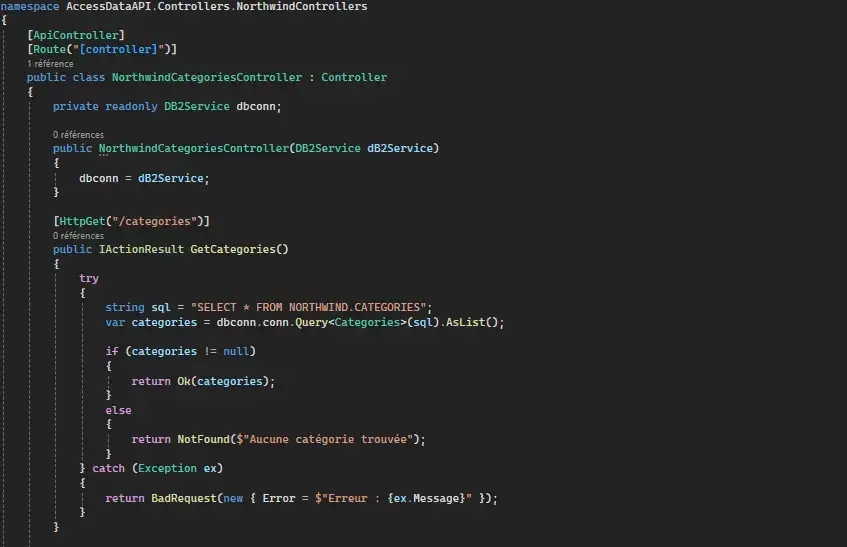
Avec les modèles et services en place, je peux ensuite créer les controllers. Ils traitent les requêtes entrantes, exécutent la logique nécessaire (CRUD) et renvoient les réponses appropriées aux clients.
Requête GET pour récupérer les catégories:
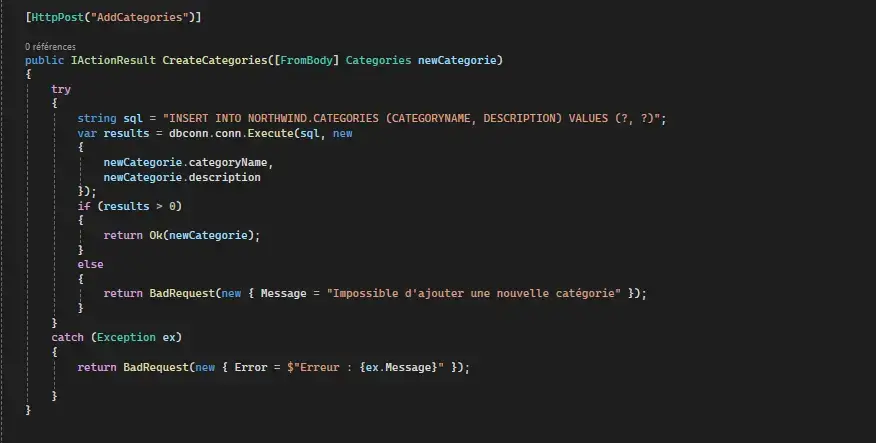
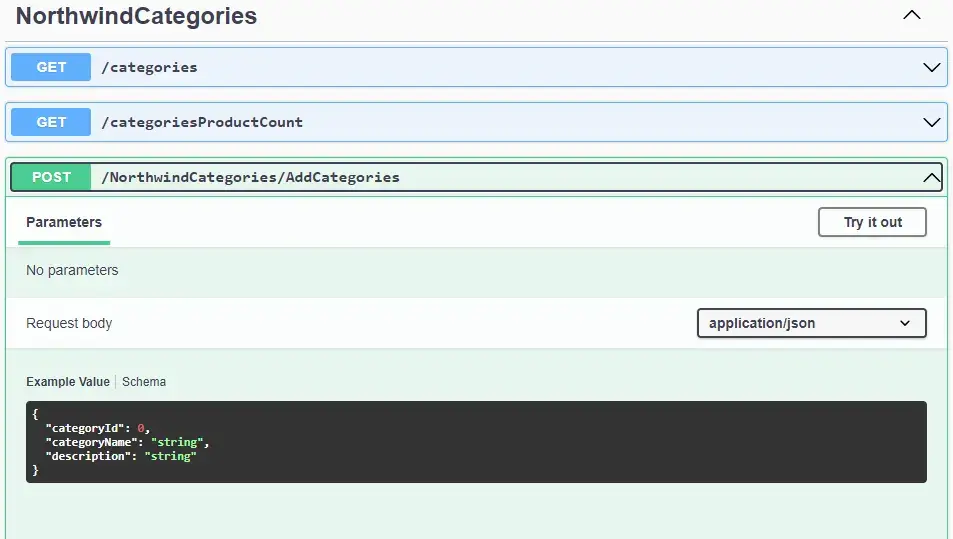
Requête POST pour ajouter une nouvelle catégorie:
Pour que les requêtes HTTP soient correctement acheminées vers les actions des controllers, j’ai mis en place un système de routing précis. Les routes associent des URL spécifiques aux actions des controllers, garantissant ainsi que chaque requête atteindra sa destination prévue dans l’API.
Résultat de la requête GET dans Swagger:
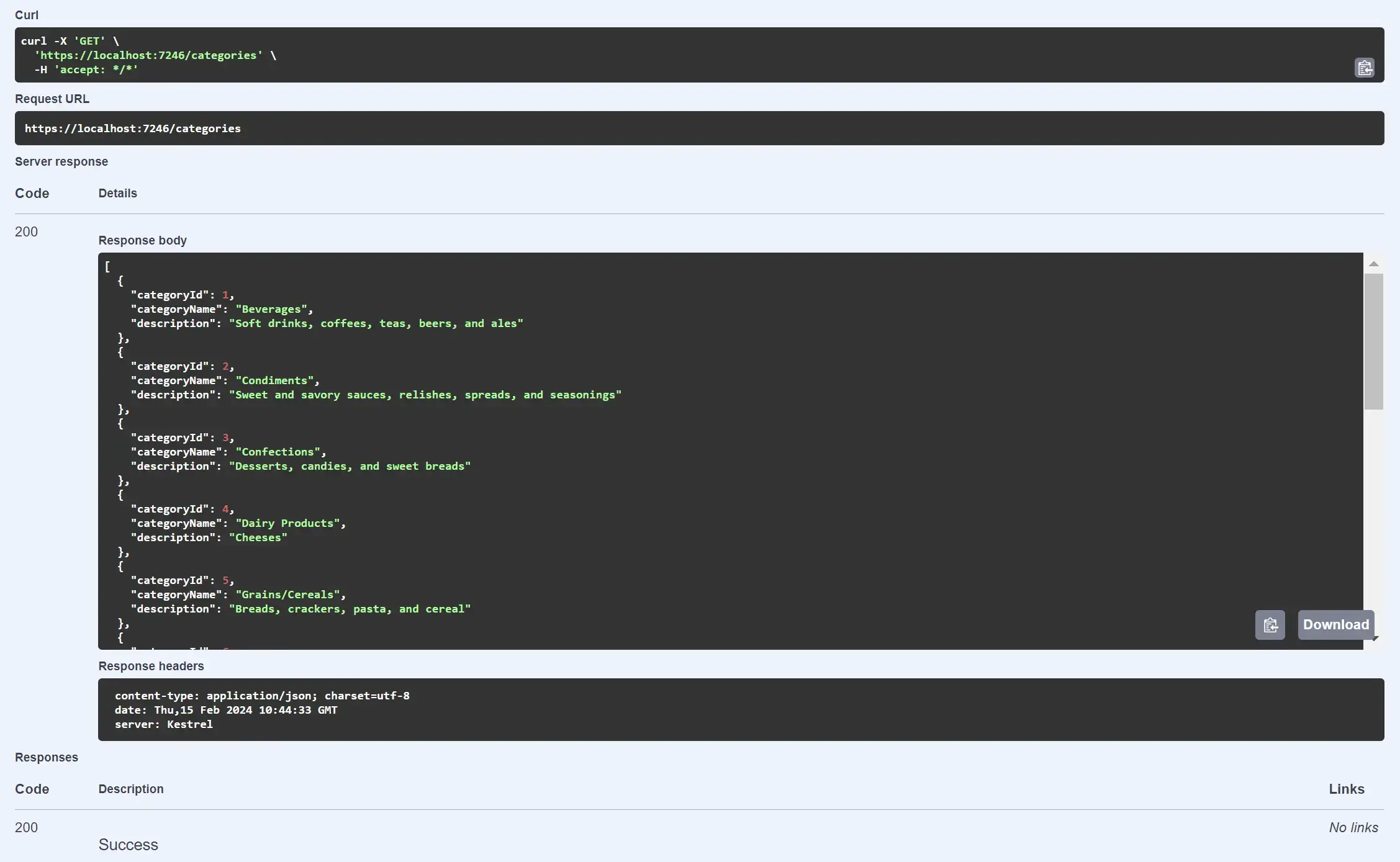
Schéma de requête dans l'API pour ajouter une nouvelle catégorie (POST)
Enfin, pour permettre à l’application externe de récupérer les données depuis l’API .NET, j’ajoute une configuration CORS (Cross Origin Resource Sharing) pour autoriser les requêtes inter-domaines de manière sécurisée, assurant ainsi à l’application Angular d'accéder aux ressources de l’API sans enfreindre la politique de même origine.
Avec l’API désormais configurée et fonctionnelle, elle est désormais prête à l’emploi et m’ouvre la voie vers la prochaine étape, la création de l’application front.
Création de l’application Angular
Etape 1 : Configuration de l’environnement Angular
Je commence par configurer l'environnement de développement nécessaire pour Angular en utilisant Node.JS et NPM, et l’installation des packages Angular Cli. Avec le modèle de conception MVVM, l’idée est de séparer la logique d’affichage de la logique métier. Cette fois, j’utilise Visual Studio Code avec lequel certaines extensions pratiques me permettent de développer plus rapidement.
Étape 2: Création des services et Modèle de données.
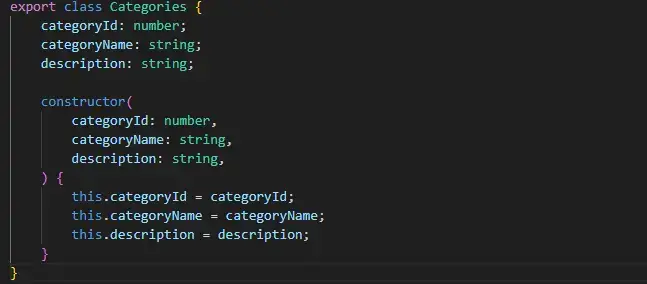
De la même manière que l’ API .NET, je crée également des modèles de données TypeScript pour une manipulation, un stockage et une utilisation plus efficace de ces données dans l’application.
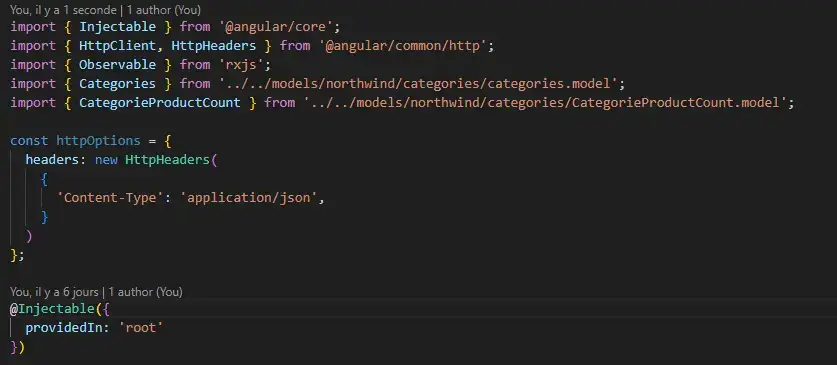
La communication avec l’API .NET est établie au travers des services proposés par Angular, utilisant le protocole HTTP pour échanger des données au format JSON.
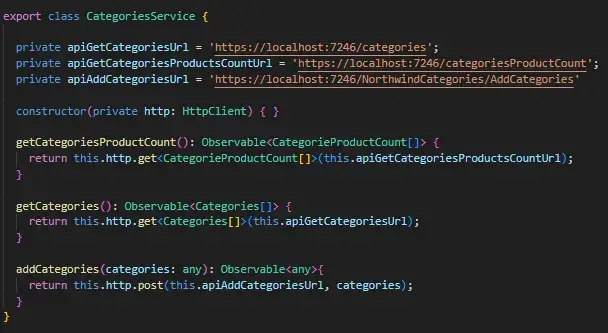
Je crée donc différents services qui servent de pont entre l’application Angular et l’API .NET. Chaque méthode utilise une URL spécifique, et je peux désormais appeler les méthodes correspondantes à chaque service directement depuis chaque composant Angular.
Etape 3: Développement des composants
Le principe même et l’intérêt d’Angular réside dans l’utilisation des composants, constitué d’un fichier TypeScript qui gère la manipulation des données et la logique métier, d’un fichier HTML pour les templates, ainsi qu’un fichier css ou scss pour le style. Ces composants peuvent être imbriqués les uns dans les autres et favorisent la modularité.
En créant des composants distincts pour différentes parties de l’interface utilisateur, j’ai pu appeler les méthodes définies dans les services Angular pour récupérer les données depuis l’API.
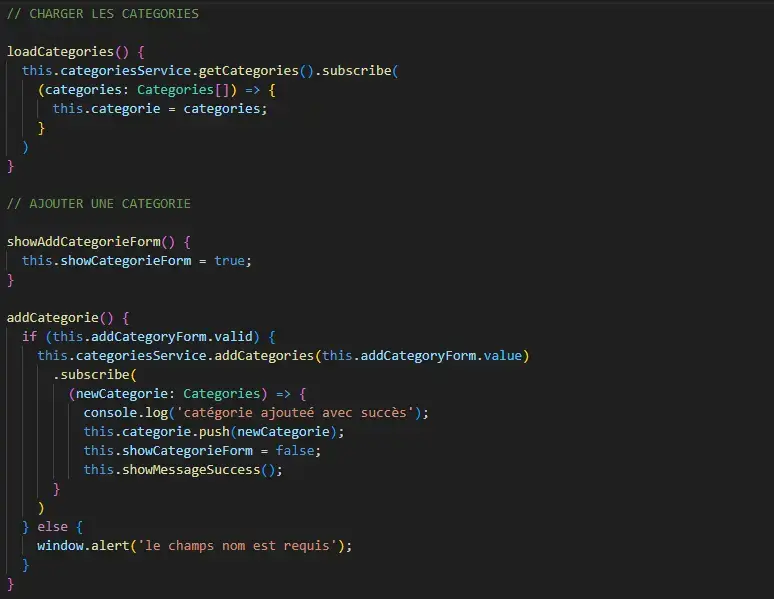
Il devient ainsi aisé de créer des graphiques ou des calculs plus ou moins complexes, répondant à des besoins spécifiques tout en bénéficiant d’une mise à jour dynamique de l'interface utilisateur avec des temps de réponses extrêmement bas.
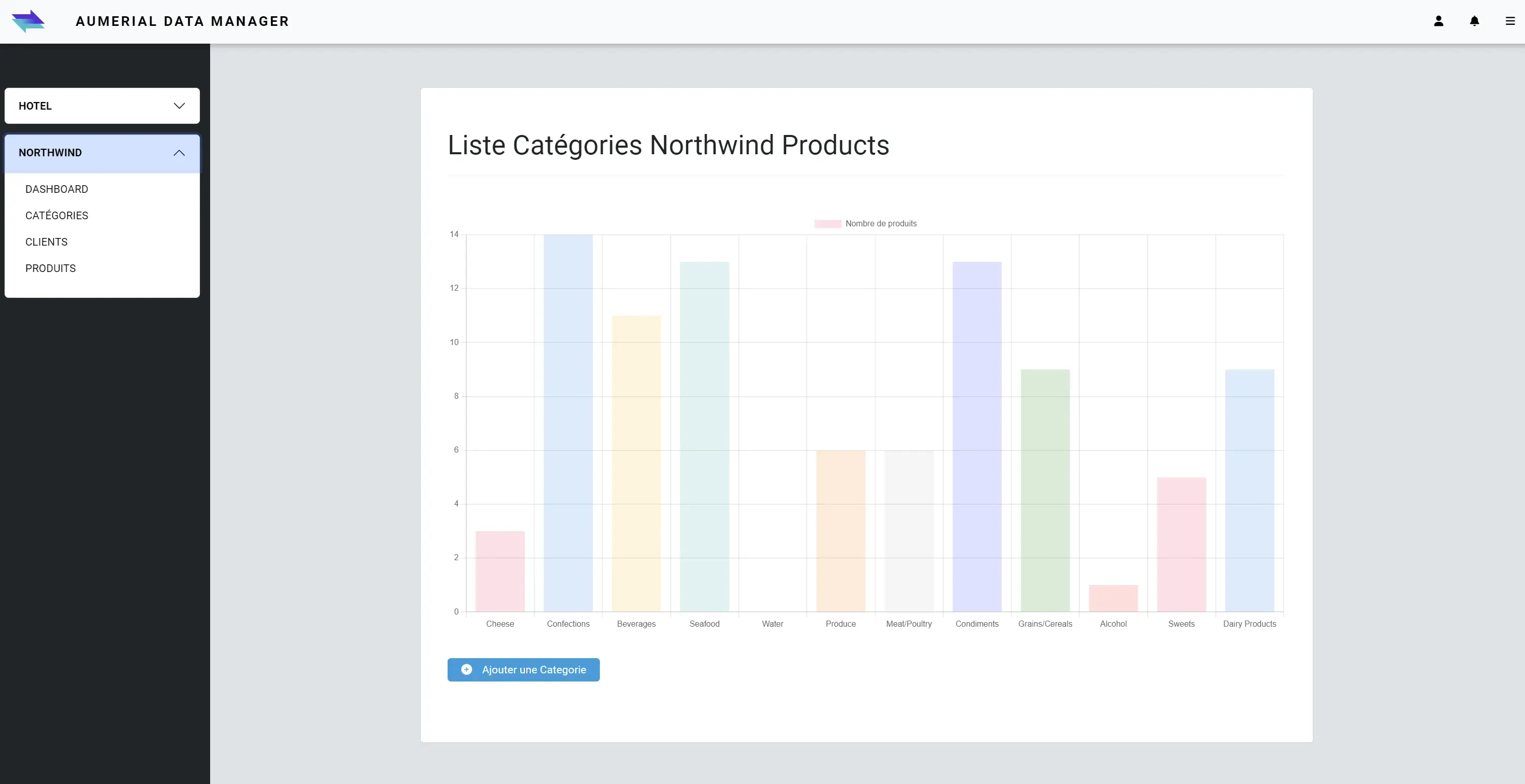
Création d'un diagramme en bâton, pour récupérer le nombre de produits par catégorie:
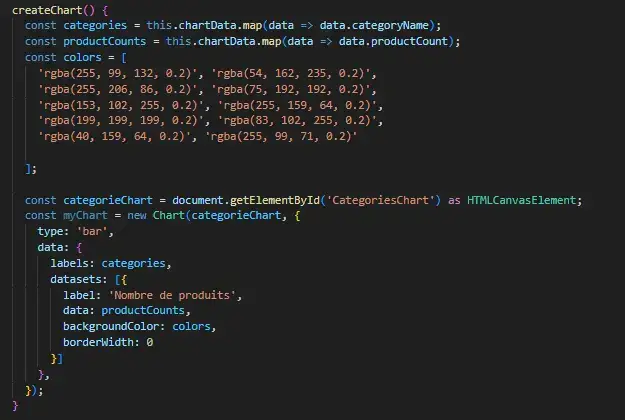
visuel du diagramme en bâton, depuis mon application front Angular:
visuel d'un diagramme circulaire présentant les stocks produits:
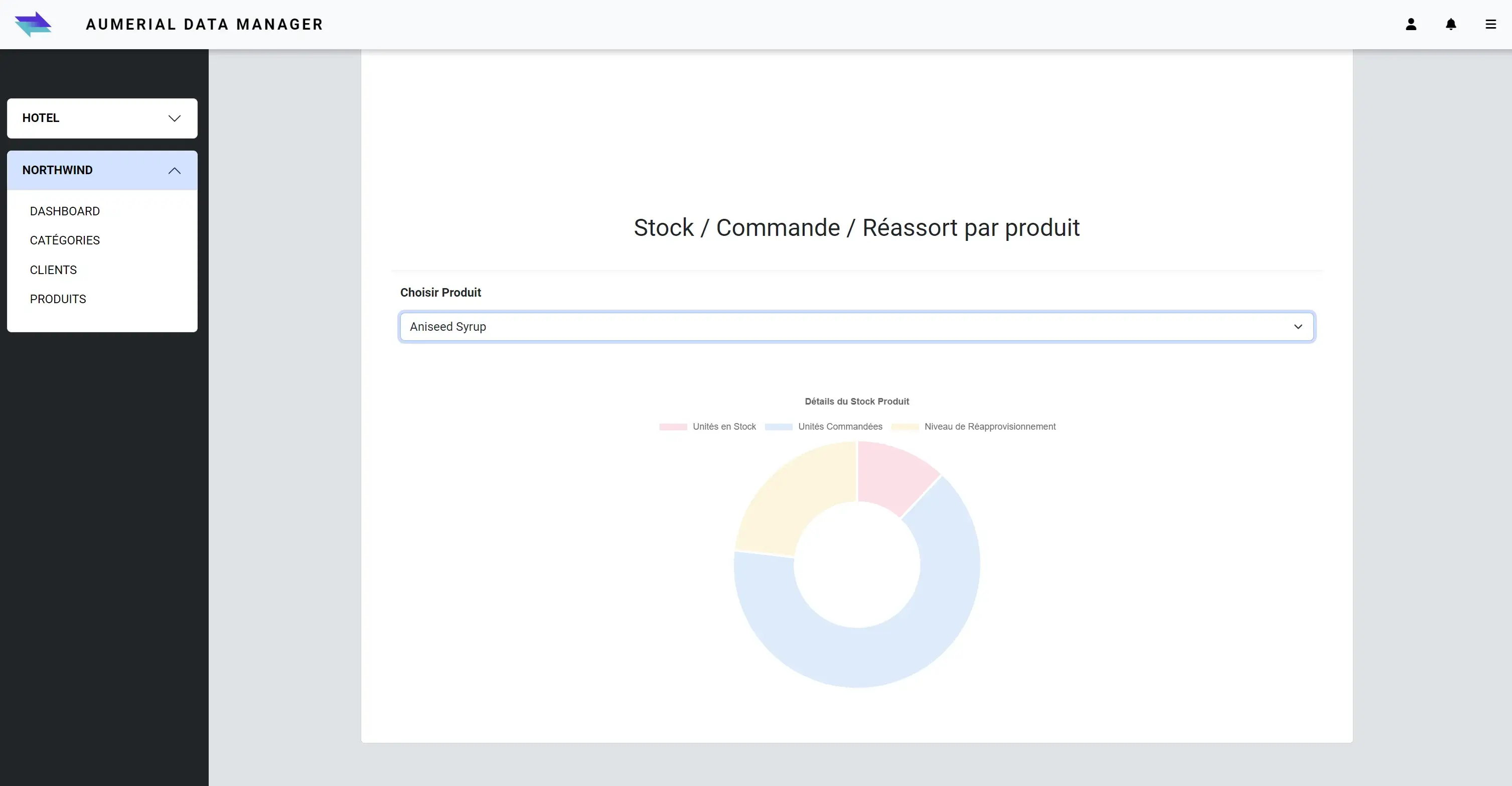
Conclusion
Ce projet illustre non seulement le gain de productivité et de modularité offert par l'écosystème .NET, mais c’est surtout la démonstration éloquente de la simplicité et l’efficacité d’NTi dans l’accès aux données sur IBM i, et pour la création d’applications client lourd.
Avec une bonne compréhension des principes de programmations orientée objet, des standards ADO .Net et bien entendu du langage SQL quel que soit le SGBD sous-jacent, le développement moderne et la communication avec diverses bases de données devient réellement accessible, facile et sans contraintes.
Ce que j’ai rapidement conçu illustre parfaitement l’une des innombrables possibilités qu’offre notre fournisseur de données Nti, qui met en évidence l’importance d’avoir un accès simplifié et rapide aux ressources de systèmes aussi robuste que l’IBM i. Ces ressources deviennent non seulement accessibles mais aussi pleinement exploitables pour le développement d’applications métiers spécifiques à chaque besoin, et ce sans complexité ajoutée.
La réalisation d’une API .NET capable de dialoguer simultanément avec DB2 for i sur une partition IBM i et une instance PostGreSQL conteneurisée sur un Raspberry Pi connecté à l’IBM i illustre bien la polyvalence et l’efficacité de notre data provider NTi à pouvoir orchestrer une communication parfaite tout en mêlant habilement ressources traditionnelles et modernes.
Quentin DESTRADE